[PostgreSQL 공부하기] PostgreSQL Index는 B-Tree를 어떻게 사용할까?
원문: https://www.qwertee.io/blog/postgresql-b-tree-index-explained-part-1/
원문: https://en.wikipedia.org/wiki/B-tree
Index의 목적은 적은 양의 데이터를 찾을때 disk I/O를 줄이는 것이다. disk를 검색하는 작업은 O(n)이지만 index가 유용하기 위해서는 그보다 더 빨라야한다.
PostgreSQL의 default index는 B-Tree로 구성되며 좀 더 정확하게는 B+ Tree로 구성된다. B-Tree와 B+ Tree의 차이점은 key가 저장되는 방식에 있다. B-Tree에서는 각각의 Key들은 leaf node이든 non-leaf node이든 딱 1번만 저장되지만 B+ Tree는 모든 Key들은 leaf node에 존재하고 non-leaf node에도 존재할 수 있다.
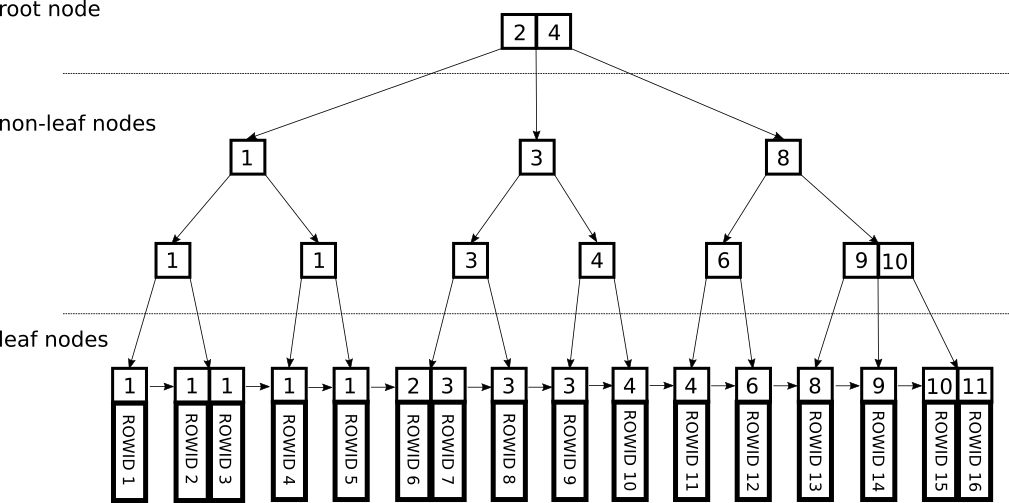
Leaf Nodes
Leaf Node는 table row을 가리키는 포인터를 가지고 있는 ROWID와 key를 가지고 있다. 각각의 leaf node사이에는 index key에 기반한 순서가 있다. 이 순서는 실제로 저장되는 physical order와는 독립적이다. physical order와 독립적이기 때문에 INSERT같은 작업을 하더라도 실제로 data를 옮기지 않고 몇개의 Pointer만을 업데이트하면 되기 때문에 작업을 빠르게 수행할 수 있다. 이렇게 logical order를 따라 저장되어 있기 때문에 오름차순과 내림차순 검색이 가능하다.
Internal Nodes(Non-leaf Nodes)
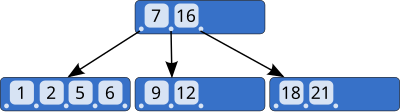
위의 사진을 보면 좀 더 쉽게 이해가 될 것 같은데 internal node에는 pre-define된 범위가 있다. 그리고 포인터들은 각각의 범위안의 노드들을 가리킨다. 즉 위의 예시에서 7보다 작은 key들이 모여져 있는 노드들을 가리키는 포인터, 7~16을 가리키는 포인터 16이상을 가리키는 포인터들이 있다.
보통 한묶음(노드)당 d~2d개의 key들로 구성이된다(d가 최소개수). 만약 2d개의 key들이 묶여있는데 한개가 추가된다면 d개로 이루어진 2묶음을 만들고, 2d+1개의 key들 중 중간값 1개를 부모 노드의 중간으로 올린다.
하나의 노드에서 파생되는 branch의 개수는 해당 노드에 포함된 key의 개수+1개이다.
B-Tree Search
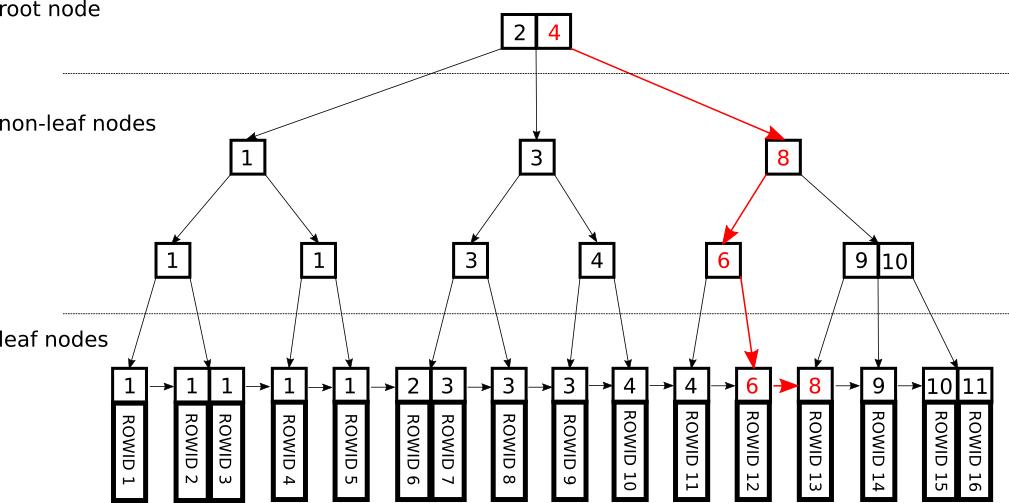
위의 예시는 key 8을 찾는 예시이다.
1. 8은 root의 모든 key들보다 크므로 마지막 포인터를 타고 내려간다.
2. 첫번째 internal node(8)와 값이 같으므로 첫번째 포인터를 타고 내려간다.
3. 두번째 internal node(6)보다 값이 크므로 마지막 포인터를 타고 내려간다.
4. 이제 leaf node에 도달했기때문에 해당 leaf node부터 쭉 오른쪽으로 타고 가면서 찾고자 하는 값보다 큰 값이 나올때까지 검색한다.
댓글
댓글 쓰기